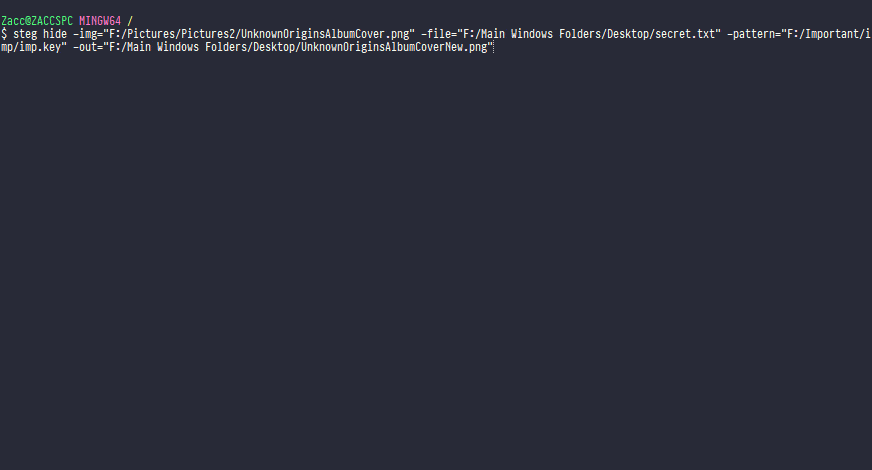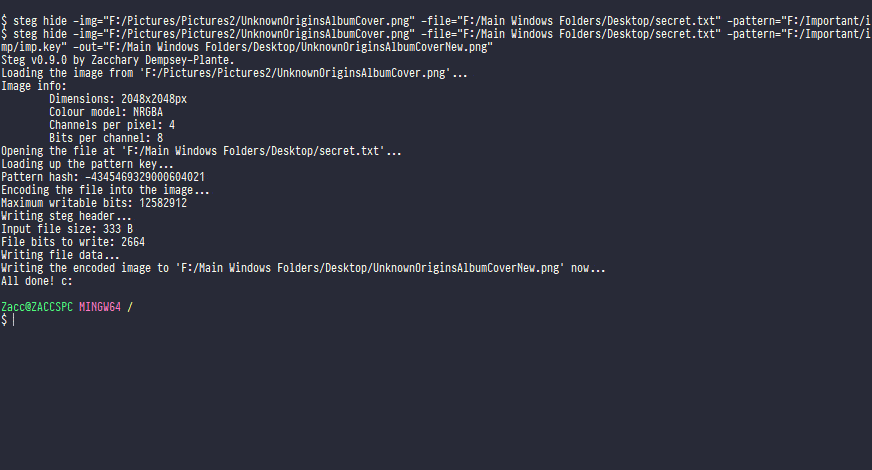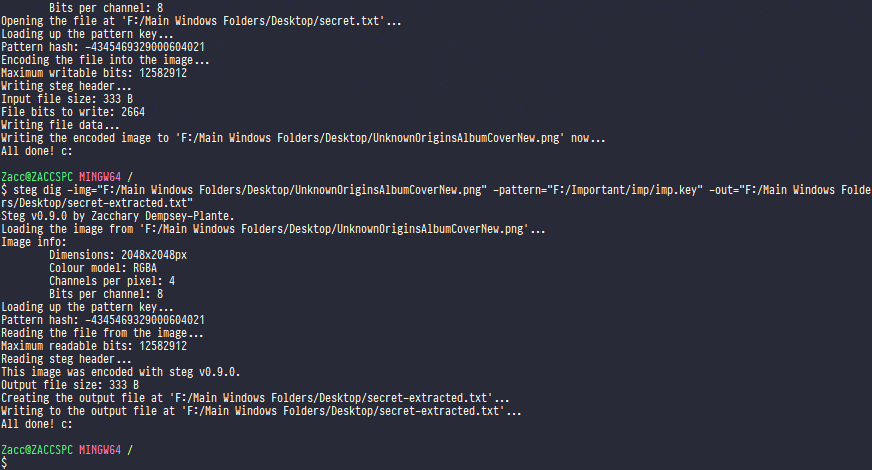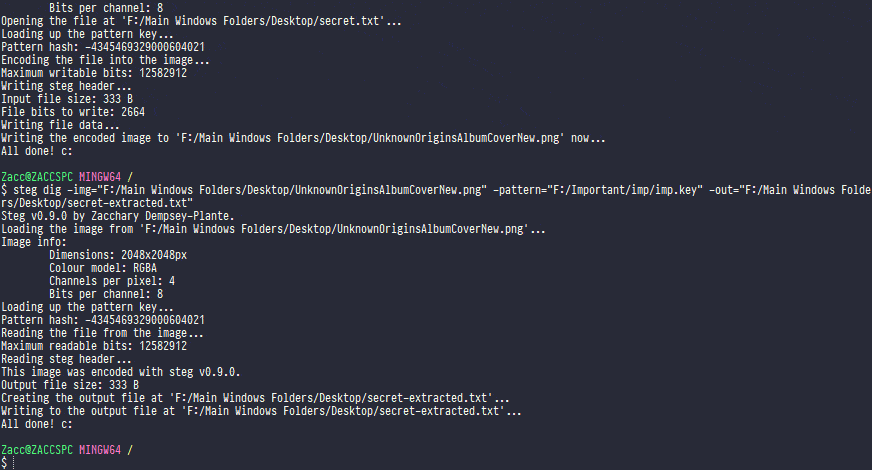
Completed - Link

Technologies Used: Blender, Photoshop
Made using the Kiara 1 Dawn HDRI from Poly Haven. Done over a few days.
It started because I wanted to make a nice custom 60% keyboard model, but I did that within a few hours and decided to make it into a full render.
I soon found that the keyboard wasn't visually interesting enough on it's own, so I decided to add in some kind of snack. That snack ended up
becoming the focal point of the image, stealing the spotlight from the keyboard.
The honey was a great opportunity to practice fluid simulation - I had the simulation emitter animated moving back and forth in a way like one
might drizzle a sauce on something, and then picked a frame of the honey sim that looked good. The crackers were also simulated just dropping on the plate,
to give them the feeling of sitting naturally. The curtains in the background were handled in a similar way. I animated them being moved into place and ran a cloth simulation to get a really
natural look.
This is my second-ever render, done in Blender with the Cycles renderer. The artwork on the keyboard is the famous Japanese woodblock print The Great Wave off Kanagawa by Hokusai.